In today’s times, viewers demand an immersive and inclusive streaming experience. Accessibility and engagement have become the key to streaming success. There was a time when captions were optional in OTT videos. But today, captions and subtitles are no longer just nice-to-haves, they’re essential for accessibility and a truly inclusive viewing experience.
At Muvi, we are committed to making your videos accessible and enjoyable for everyone. That’s why we leverage the power of AWS Transcribe to deliver real-time speech-to-text capabilities.
In this blog, we’ll explore how AWS Transcribe works behind the scenes, transforming spoken words into on-screen text. We’ll discuss how you can automate the process and how it enhances the viewing experience for all audiences. So, let’s get started!
What is AWS Transcribe?
AWS Transcribe is a service that converts spoken words into text. This tool offers a convenient and effective method for transcribing audio content into written form. It supports a variety of audio formats, making it suitable for various applications like transcribing customer service calls, interviews, and meetings.
To utilize Transcribe for tasks like meeting transcription, you must have an AWS account. You can access Transcribe through the AWS Management Console, AWS Command Line Interface (CLI), or AWS SDKs. Before you begin transcribing, ensure that you have the appropriate permissions to utilize the Transcribe service.
How Does Speech-To-Text Work?
Speech-to-text software operates by listening to audio and providing an editable, verbatim transcript on a designated device. This software achieves this through voice recognition. It employs linguistic algorithms within a computer program to differentiate auditory signals from spoken words and convert those signals into text using Unicode characters.
The conversion process from speech to text involves a sophisticated machine-learning model that comprises several stages. Let’s delve deeper into how this process unfolds:
- When a person speaks, their vocal cords produce vibrations that create sounds. Speech-to-text technology functions by detecting these vibrations and converting them into digital language using an analog-to-digital converter.
- The analog-to-digital converter captures sounds from an audio file, meticulously measures the waveforms, and filters them to isolate the relevant sounds.
- These sounds are then segmented into hundredths or thousandths of seconds and matched to phonemes. A phoneme is the smallest unit of sound that distinguishes one word from another in a language. For example, English has approximately 40 phonemes.
- The phonemes are processed through a network using a mathematical model that compares them to well-known sentences, words, and phrases.
- Finally, the output is presented as text or a computer-generated voice, such as those produced by advanced AI voice generator systems, based on the most probable interpretation of the audio.
Top Features
Let’s take you through some of the top features of AWS Transcribe service.
On-demand & Live Streaming Content Support
You need just a single service API for managing both on-demand and live-streaming content. Supported formats for on-demand videos include FLAC, MP3, MP4, Ogg, WebM, AMR, or WAV. For live streaming, the API supports formats such as HTTP2 and WebSocket.
The list of audio codecs supported has been sorted from best quality to worst quality below:
- FLAC (lossless)
- WAV (lossless)
- MP3 (lossy)
- MP4 (lossy)
- Ogg (lossy)
- WebM (lossy)
- AMR (lossy)
Custom Language Models (CLM)
Enhance the accuracy of AWS Transcribe by incorporating domain-specific terminology, such as names, acronyms, and slang, using custom vocabulary and CLM. For batch processing (VoD), custom vocabulary and CLM can be utilized to achieve the highest accuracy levels.
Live Streaming Subtitle Stabilization
Improve the live subtitling experience in video broadcasts and in-game chat by controlling the stabilization level of partial transcription results. This provides the flexibility to display partial sentence results instead of waiting for the entire sentence to be subtitled.
WebVTT and SubRip Support
Output batch transcription works in WebVTT (.vtt) and SubRip (.srt) formats. They can be used as video subtitles in existing workflows. Output files include any content redaction, vocabulary filters, and distinguishing multiple speakers in both formats.
Vocabulary Filtering
A high-quality user experience is maintained by filtering specific slang, profanity, or inappropriate terminology. You can create and utilize multiple vocabulary filter lists to create subtitles suitable for adult or child audiences based on tags.
Multilingual Subtitle Options
You can provide subtitles in multiple languages or translate generated subtitles for content localization with Amazon Transcribe. It helps you extend the reach of your content. Amazon Transcribe supports multiple languages, reducing the need for diverse language expertise.
How to Use AWS Console for the Transcribe Process?
To use AWS Console for the Transcribe process, you need to follow the steps given below:
1. First Extract an Audio file in high quality from the Target Video File. On-demand/batch supported formats include FLAC, MP3, MP4, Ogg, WebM, AMR, or WAV. You can use Handbrake, ffmpeg, or any other tools to extract the Audio track. Then upload the audio file to the S3 bucket.
2. Choose “Amazon Transcribe” from the “Services” Menu in the AWS Console.
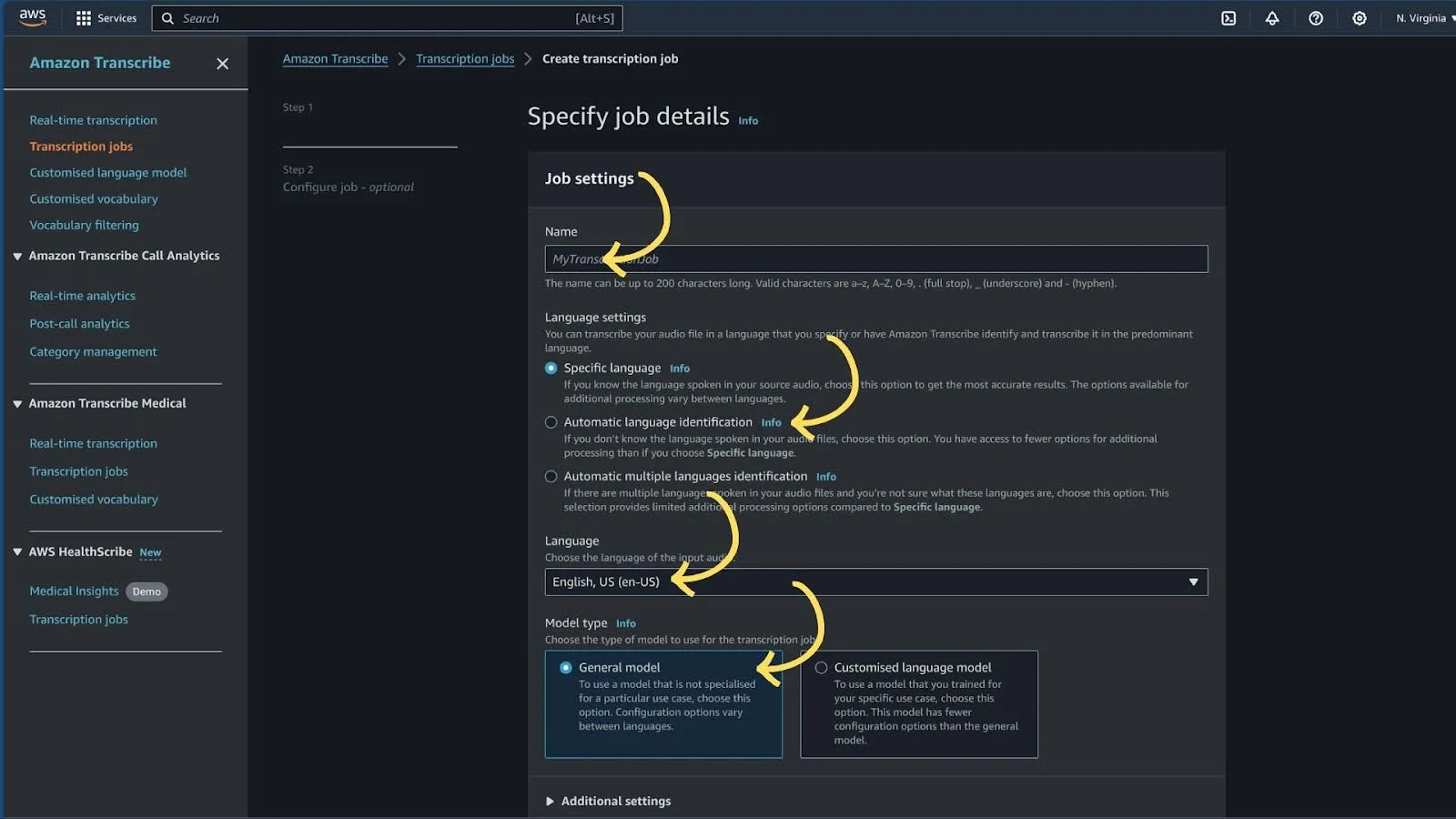
3. Provide the s3 URL of the source from which we need to generate a Caption file.
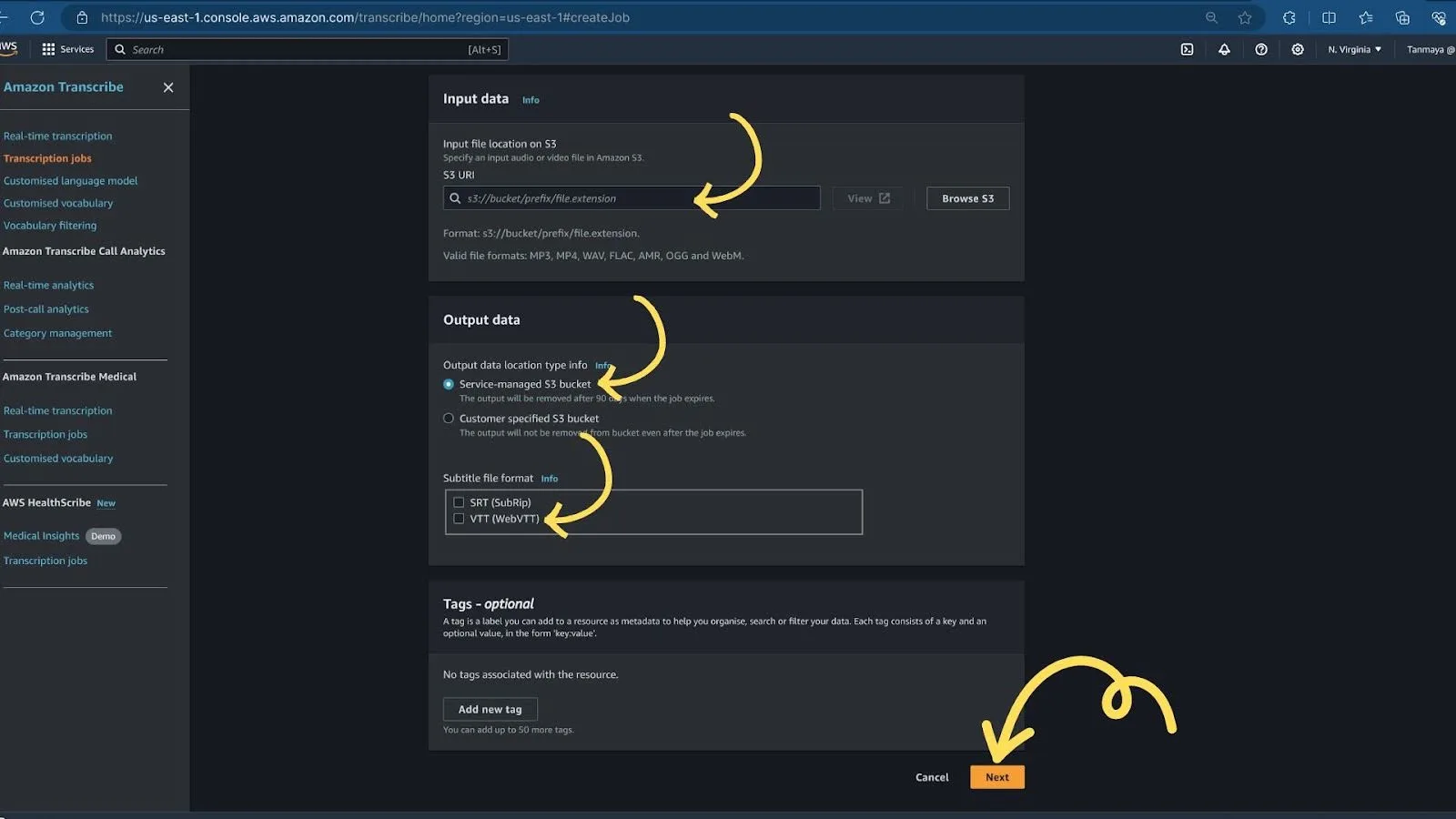
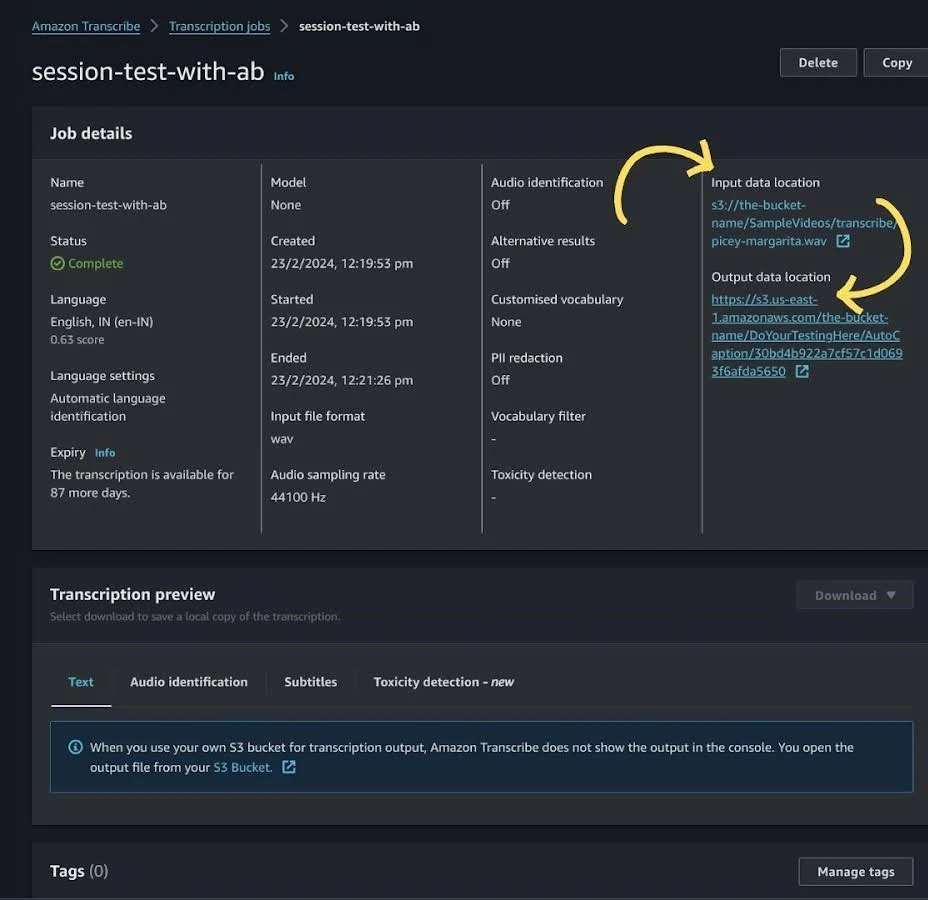
4. After clicking on “Next,” AWS Transcribe will process your audio file and take some time to generate a subtitle file based on the data provided during the previous steps. Once the process is complete, you will see a screen like the one below, which will display the output directory of the subtitle file.
How to Use AWS SDK for the Transcribe Process?
Here is the sample PHP Code for using AWS SDK for the Transcribe Process:
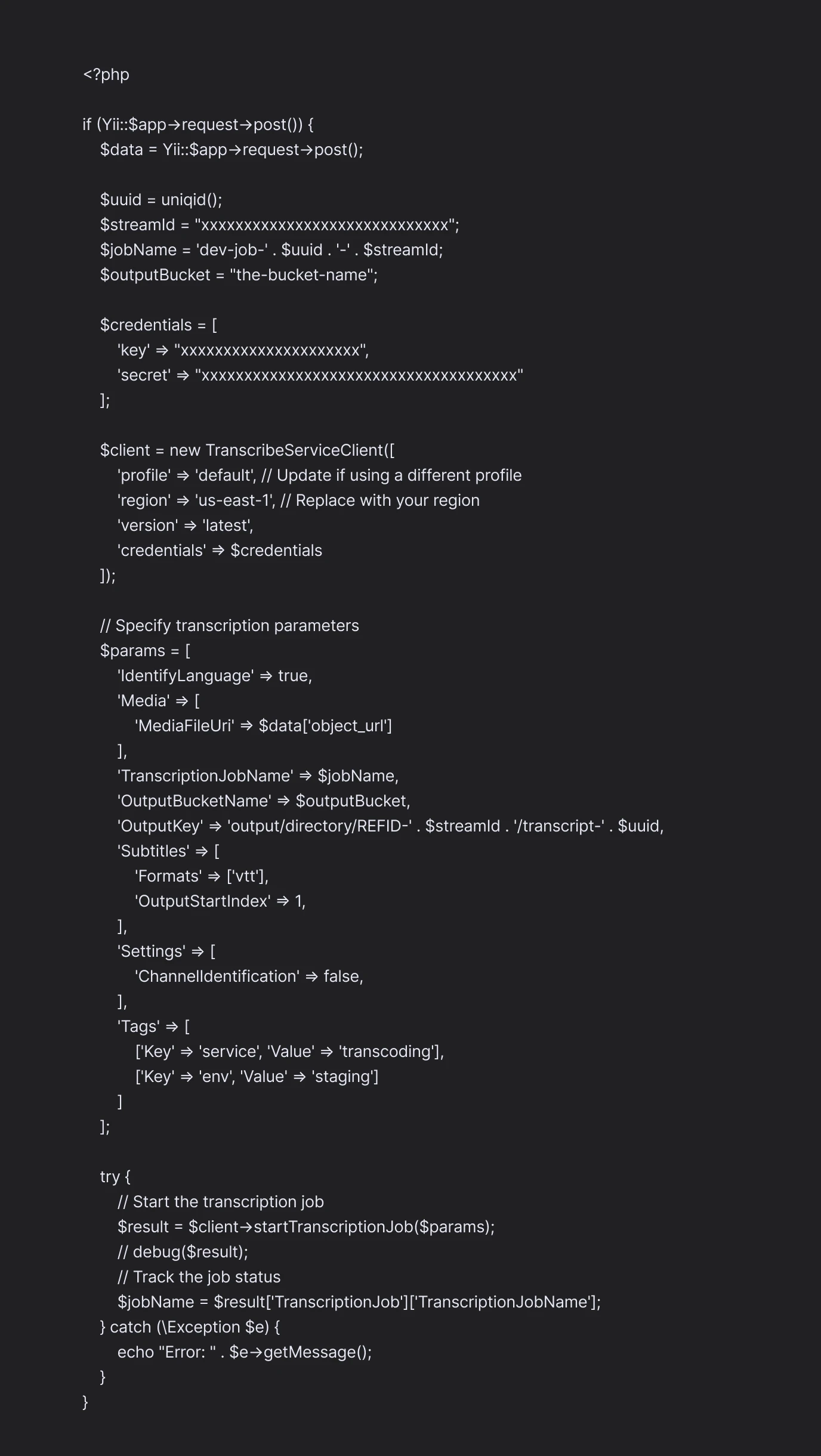
You can refer to the official AWS documentation to know more about the process in detail.
How to Use AWS CLI for the Transcribe Process?
To start a new transcription, use the start-transcription-job command.

Amazon Transcribe responds with:

To understand it more clearly, you can refer to the AWS CLI page.
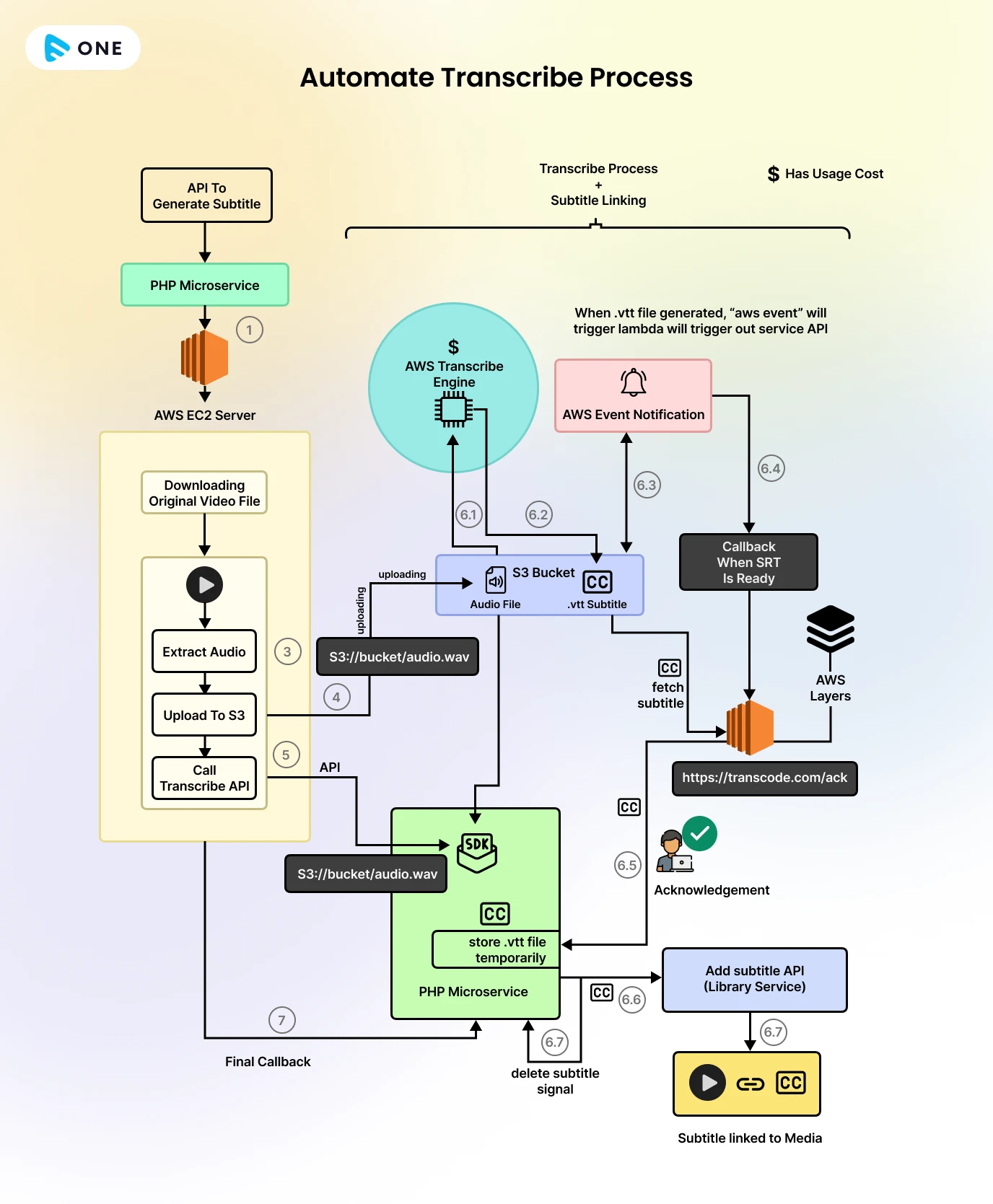
How to Automate the Transcribe Process?
Here are the steps to automate AWS Transcribe with PHP:
- Setup S3 Bucket: Create an S3 bucket where you will upload your video/audio files for transcription.
- Configure AWS Event Notification: Set up AWS Event Notification on the S3 bucket to trigger an event whenever a new file is uploaded. This event will be used to store details in your database using PHP logic.
- Create a Lambda Function: Develop a Lambda function that will be triggered by the AWS Event Notification when AWS Transcribe completes its job. This function will store the output of the transcription in the specified S3 bucket.
- Create an API: Build an API that accepts a video file URL. This API will call the Lambda function to launch an EC2 server. Inside the EC2 server, the audio track will be extracted and uploaded to the S3 bucket. Once the audio file is stored in the bucket, another API will be called to initiate the Transcribe job using the AWS SDK.
- Process Transcription Job Completion: After the Transcribe job finishes, AWS will store the output VTT/SRT file in S3. The AWS Event Notification will notify your microservice, where you will write logic to store all details in a database. You can then use these details to show the status of the process.
These steps will help you automate the transcription process using AWS Transcribe and PHP. The entire process has been depicted in the flow diagram given below.
Wrapping Up
In this blog, we saw how AWS Transcribe can be used to convert speech to text, and how it can be used to automate the captions and subtitles in streaming. By doing so, you can deliver a better streaming experience to your viewers, make your videos more accessible and localized, and hence increase the reach and revenue of your streaming business.
If you are looking for a streaming SaaS solution that helps you build your own-branded streaming platform with over 500 industry-leading features, including automated captions and subtitles, out-of-the-box, without any coding, then Muvi One is the right choice for you. And you can try it for FREE for 14 days, without giving away your credit card details! So, why wait? Sign up to start your 14-day FREE trial today.









Add your comment